Performance of the Java sorting algorithm (ctd)
On the previous page, we consider some features of
the Java sort algorithm which may affect its performance and suitability with a given set
of data. Now without further ado, let's dive in and look at some actual performance measurements
of Collections.sort(). Figure 1 shows the mean sort time for an n-element list of random integers
on my test system.
(Each measurement is actually the observed time in nanoseconds to sort 50,000 lists of the
given size pre-filled with random integers, but it's the relative performance that
really interests us.)
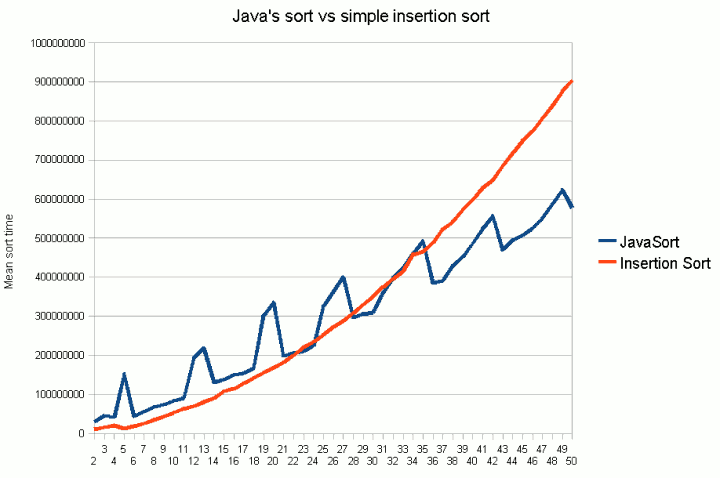
For comparison, I also measured the time to sort using a simple insertion sort. In each run, two
copies of the 50,000 test lists were thus made. Then one copy was sorted with Collections.sort()
and the other with our insertion sort method.
The graph shows that compared to the insertion sort, Java's mergesort scales better overall.
But it also involves some more complex operations:
- it copies the contenst of the list into an array;
- it makes a further copy (a clone) of that array;
- it makes recursive calls.
Although the insertion sort scales poorly overall, for small amounts of data (up to about 30-35 items
on our test system), it actually performs better. This is because the insertion sort (a) sorts everything
in situ (doesn't need to copy objects into an array or take a clone); (b) runs in a loop
comprising simple operations rather than making recusrive calls. After a certin list size, we hit
a point where the "extra hoops" needed for performing the mergesort pay off. At some point, the algorithm that involves
individually more complex operations but scales better wins out over the simpler but less scalable one.
So what does this mean in practice?
In a few, specific cases, Java's default sort algorithm may not be the most suitable. If you
are sorting very small lists a very large number of times, then implementing a
non-recursing, in situ sort such as an insertion sort may give better performance1
Sorting in parallel
One potential way of improving sort performance on large-ish data sets is to sort in
parallel on multiprocessor machines. In the Java threading section of
this web site, we discuss using CyclicBarrier to
coordinate a parallel sort, which the data to be sorted is divided amongst various threads.
1. As a real-life example, I actually first hit upon this problem while writing the AI engine for a board
game. Part of the algorithm involved repeatedly sorting small lists of candidate moves in order to
pick the best ones. On profiling
the code, I found that the majority of time was being spent inside the call to clone
the array prior to sorting!
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.