Synchronization, concurrency and multitasking: why is it difficult? (ctd)
Processor architecture in more detail
On the previous page, we saw a very broad illustration of a number of
processes competing for a smaller number of CPUs, which in turn competed for
memory and other resources. There are actually a few more details of memory
and processor architecture which are worth understanding if we are to
fully understand certain synchronization and concurrency issues in Java
(and other languages). The following diagram shows a theoretical processor
in a bit more detail:
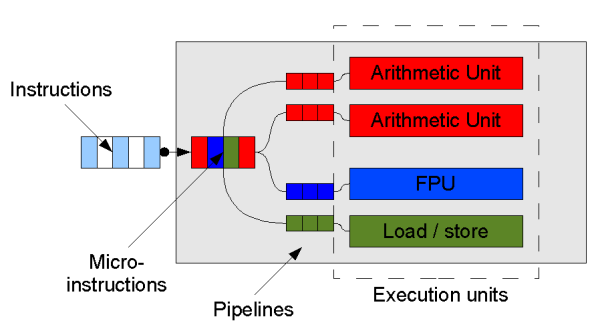
A stream of machine code instructions is fetched from memory (usually
via a cache) and on many processors decoded into a series of micro-instructions.
(These stages are generally pipelined: fetching of one instruction
happens while the next is being decoded, and indeed on some processors such
as the latest Pentiums, instruction processing is split in this way into
quite a large number of parallel stages.)
These micro-instructions are a sub-level of machine code, which decompose
complex instructions into their component parts. For example, the following
instruction meaning "add to the value in the memory location pointed to by R0
the value in R1":
might be decomposed into the following sequence of
micro-instructions:
LDR A, [R0] // Load the value in memory location R0
ADD A, R1 // Add R1 to the value
STR A, [R0] // Store the result back in memory
(In other cases, such as a simple add, a machine code instruction may correspond
to exactly one micro-instruction.)
The resulting stream of micro-instructions is then sent off to the corresponding
components of the CPU– generally termed execution units–
such as the arithmetic unit to handle addition, and a load/store unit to
interface with memory. The functionality of many modern processors is split up
in this way. What the exact repertoire of execution units is depends on the
specific processor. But on most processors, including modern Intel processors,
the upshot is that, with judicious ordering
of instructions, the processor can actually execute several at once.
So even a humble single-processor machine may actually doing concurrent
processing at some level1. (On some processors,
as in our example here, there is more than one arithmetic unit since
integer arithmetic instructions such as add and subtract are very common and
often occur in sequence.)
Now, for this concurrent execution of instructions to work effectively, we
need to try and make sure that in the stream of (micro-)instructions, we
don't "hog" a particular execution unit. Consider, for example, if we have
a bunch of floating point operations followed by a bunch of integer
operations. There is a risk that the integer operations will sit at the
back of the queue waiting for the floating point operations complete, and in the
meantime our processor has two integer arithmetic units sitting twiddling their thumbs.
An alternative is to interleave the floating point and integer instructions,
so that floating point and integer instructions can be executed in parallel. (Of course,
if the integer instructions rely on the result of the floating point ones, this
optimisation may not be possible.)
Modern compilers and indeed modern processors work to try and order instructions
for optimal performance. What this means is that things don't always happen
when you think they will. We may perceive of "incrementing a variable"
as a simple load-add-store sequence. But in reality, a variable may be fetched
early or stored late in the sequence of instructions in order to improve the
chances of different execution units working in parallel.
Next...
On the next page, we begin a review of synchronization and concurrency before Java 5.
Notes:
1. Another possibility which we don't illustrate here
is that some processors can actually execute in parallel instructions from
different threads, e.g. thread 1 executes an add while thread 2
executes a load from memory. Intel have branded this Hyper-Threading
in their recent processors (although the basic idea is not new and
appears to date back to at least as early as the 70s).
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.