Performance of string tokenisation: String.split() and StringTokenizer compared
As noted in our introduction to the String.split() method, the latter is around twice as slow as a bog-standard StringTokenizer, although it is more flexible.
Compiling the pattern
Using String.split() is convenient as you can tokenise and get the result
in a single line. But it is sub-optimal in that it must recompile the regular expression
each time. A possible gain is to compile the pattern once, then
call Pattern.split():
Pattern p = Pattern.compile("\\s+");
...
String[] toks = p.split(str);
However, the benefit of compiling the pattern becomes marginal the more
tokens there are in the string being tokenised. The graph below shows the time
taken on one test system (2GHz Pentium running JDK 1.6.0 under Windows) to tokenise 10,000
random strings consisting of between 1 and 19 5-character tokens separated by
a single space1.
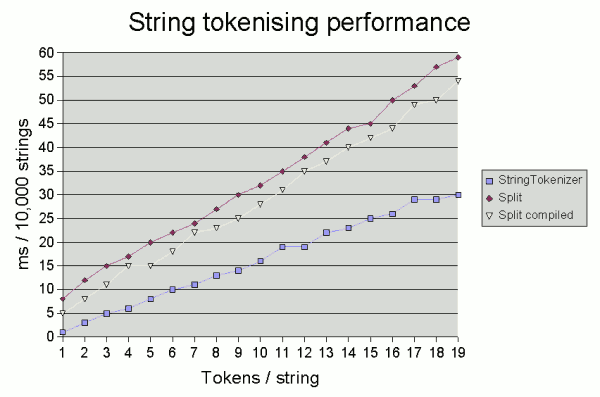
Now, what these results highlight is that whatever method you use, there's
also no need to panic unless you're doing a lot of tokenisation:
even the fairly extreme case of tokenising 10,000 19-token strings took just
60 milliseconds. However, if you are doing a serious amount of tokenising
(for example, in some of my corpus linguistics work, I frequently process corpora consisting
of millions of words and occasionally shaving time off the "nuts and bolts" of parsing can
be useful), then the good old StringTokenizer may still be worth
using for performance reasons. If you can cope with its restrictions, of course.
The results above suggest that compiling the pattern is comparatively most beneficial if
you are tokenising a large number of strings each with few tokens.
1. Each figure is an average of ten runs. The three tests were interleaved in each run, and 3 dummy runs preceded the timed runs to allow the JIT compiler to "warm up".
The code to parse a single string was in each case coded as a separate method, so that this method
would become "hot".
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.