ConcurrentHashMap scalability
As mentioned in our introduction
to ConcurrentHashMap, the purpose of ConcurrentHashMap is to reduce the lock contention
that would normally occur when multiple Java threads access the same HashMap
simultaneously. Therefore, it provides higher throughput: threads can operate simultaneously on different parts
of the data structure and therefore have less change of "blocking" or competing with one another for access to the map.
But how much more efficient is a ConcurrentHashMap— compared to an ordinary synchronized map?
To measure the performance benefit and scalability of ConcurrentHashMap, we can run an
benchmark experiment. Our experiment simulates a case where a number of threads simultaneously "hit" a map, adding and
removing items at random. Each thread sits in a tight loop choosing a random key and seeing if that
key is in the map. If not, the thread has an approximately 10% chance of
adding a mapping of that key to the map; if the key is already mapped, there
is a 1% chance that the mapping will be removed. After running 2,000
iterations, each thread sleeps for a small random number of milliseconds before
running the loop again. Thus, the program aims to simulate a moderate-ish
amount of contention on the map, as might be experienced by an important
cache map on a busy server.
Despite each thread performing enough accesses to create contention on
the synchronization lock, very little CPU is consumed by each one. This means
that in theory, with each new thread added, we would expect almost the same
additional throughput.
Figure 1 below shows the actual behaviour of (a) an ordinary synchronized hash map
and (b) a ConcurrentHashMap being concurrently accessed by a number of
threads, running on a machine with an Intel i7-720QM processor (4 cores hyperthreading,
effectively supporting a maximum of 8 hardware threads).
The throughput measurement is the total number of
accesses (actually, the number
of blocks of 2,000 accesses) to the map performed by all
threads together in two seconds1.
We see that scalability of the synchronized hash map rapidly tails off
shortly after the number of threads reaches the number of supported hardware threads. On the
other hand, ConcurrentHashMap remains scalable: even with a relatively high
number of threads, ConcurrentHashMap behaves close to the ideal:
that is,
having n threads gives an almost n times increase in throughput.
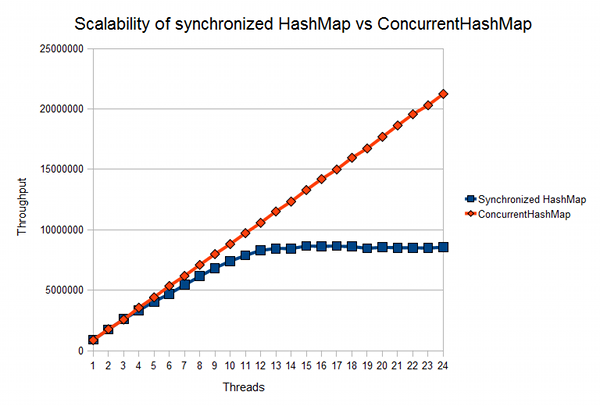
Figure 1 The scalability of ConcurrentHashMap over a regular synchronized
HashMap, illustrated by the relative throughput of a contended map implemented
with each. Measurements made under on an Intel i7-720QM (Quad Core Hypterthreading)
machine running Hotspot version 1.6.0_18 under Windows 7.
The concurrency parameter
When constructing a ConcurrentHashMap, you can pass in a
concurrency parameter which is intended to indicate "the estimated
number of concurrently updating threads". In the test described above, we
always pass as this parameter the maximum number of threads used in the
experiment.
Note that we didn't reproduce in this test the results of a previous
experiment in which overestimating the concurrency parameter gave a slight
increase in throughput. That previous experiment was
conducted under somewhat different conditions:
a dual processor Xeon server (i.e. a dual processor
hyperthreading machine), an older version of the JVM (Java 1.5.0_08)
and a different operating system (Linux) and for reference the results
are given in Figure 2 below.
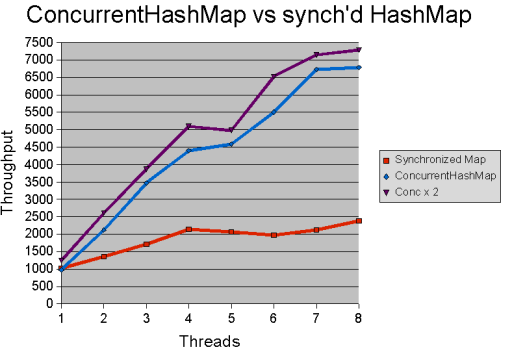
Figure 2: Results of the map throughout test on Hotspot version 1.5.0_08 under Linux on
a dual processor hyperthreading (Xeon) machine.
In a similar experiment, but with more contention
on the map, Goez et al Java
Concurrency in Practice (pp. 242-3) report essentially similar results on
an 8-processor Sparc V880, but in their case the throughput of the synchronized
HashMap plateaus even more quickly (and throughput with ConcurrentHashMap also
plateaus eventually).
More on using ConcurrentHashMap
Now we have seen the performance benefits of ConcurrentHashMap, on the next page,
we'll look further at the functionality of
ConcurrentHashMap, with details of how atomic updates to the map are performed.
1. Of course, as generally with all the experiments reported on
this site, we actually take the mean time over a number of runs of the test
(in this case, the mean measurement over ten runs is taken in each case).
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.