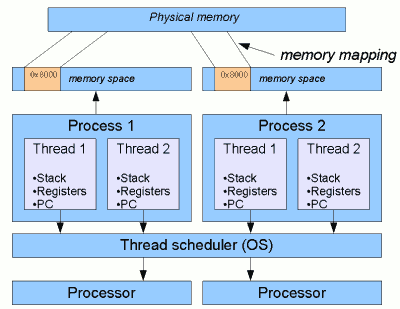
Figure 1: Typical relationsip between
threads and processes.
Threads and processes
A thread is essentially a subdivision of a process, or "lightweight process" (LWP)
on some systems. A process is generally the most major and separate unit of execution
recognised by the OS. The typical relationship between processes, threads and various other elements of the OS are shown in Figure 1 opposite. This shows two processes, each split into two threads (a simplistic situation, of course: there will be typically dozens of processes, some with dozens or more threads).
Crucially, each process has its own memory space. When Process 1 accesses some
given memory location, say 0x8000, that address will be mapped to some physical memory
address1. But from Process 2, location 0x8000 will generally refer to a completely different portion
of physical memory.
A thread is a subdivision that shares the memory space of
its parent process. So when either Thread 1 or Thread 2 of Process 1 accesses "memory address 0x8000",
they will be referring to the same physical address. Threads belonging to a process usually share
a few other key resources as well, such as their working directory,
environment variables, file handles etc.
On the other hand, each thread has its own private stack and
registers, including program counter. These are
essentially the things that threads need in order to be independent.
Depending on the OS,
threads may have some other private resources too, such as thread-local storage
(effectively, a way of referring to "variable number X", where each thread has its own
private value of X). The OS will generally attach a bit of "housekeeping" information to each
thread, such as its priority and state (running, waiting for I/O etc).
The thread scheduler
There are generally more threads than CPUs. Part of a multithreaded
system is therefore a thread scheduler, responsible for
sharing out the available CPUs in some way among the competing threads.
Note that in practically all modern operating systems, the thread scheduler is part
of the OS itself.
So the OS actually "sees" our different threads and is responsible for the task
of switching between them2.
The rationale for handling threading "natively" in the OS is that the OS is likely to have
the information to make threading efficient (such as knowing which threads are waiting for
I/O and for how long), whereas a software library may not have this information available.
In the rest of our discussion, we'll generally assume this native threads model.
Next: scheduling and its implications for Java
On the next pages, we look at
1. Things are usually a little more complex, in fact. For example, a memory
address can actually be mapped to something that isn't memory (such as a portion of a file,
or device I/O). For this reason, the term address space is often preferred.
2. An alternative scenario, less common nowadays, is that
the OS schedules at some higher level, e.g. scheduling processes, or scheduling some kind
of "kernal thread" which is a unit bigger than our applications threads. In this model,
sometimes called "green threads", threads are to some extent "artificially" handled by
the JVM (or the threading library that it is compiled against). In general, if you are using
Java 1.4 onwards on Windows or on Solaris 9 or Linux kernel 2.6 or later, then there
will be a 1:1 mapping between Java Threads and "native" operating system threads.
If you enjoy this Java programming article, please share with friends and colleagues. Follow the author on Twitter for the latest news and rants.
Editorial page content written by Neil Coffey. Copyright © Javamex UK 2021. All rights reserved.